
Революционная модель синтеза речи от Alibaba
Команда Qwen от Alibaba представила нейросетевую модель Qwen3-TTS, способную клонировать голос по короткому 3-секундному образцу. Эта технология имеет потенциал изменить подход к созданию аудиоконтента.
Как это работает?
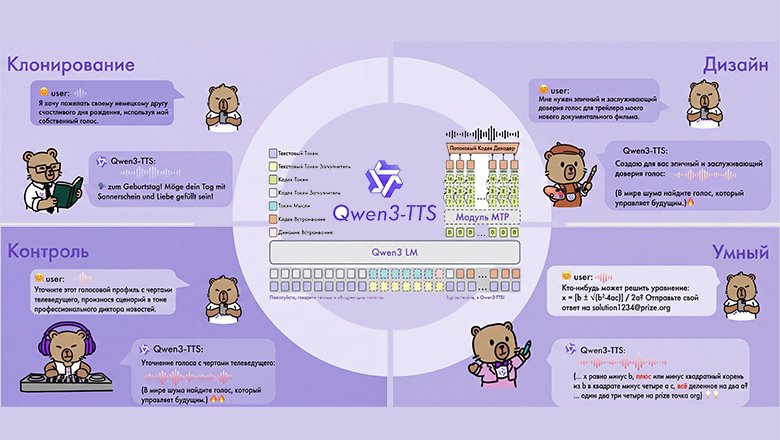
Qwen3-TTS основана на End-to-End архитектуре с дискретным многоканальным токенизатором речи. Это означает, что модель обрабатывает информацию напрямую, без потери данных на каждом этапе, как в традиционных системах.
Возможности модели
- Клонирование голоса по 3-секундному образцу
- Создание новых голосов по текстовому описанию
- Поддержка русского языка
- Работа с 10 языками, включая китайский, английский, японский и другие
Применение Qwen3-TTS
Эта технология может найти применение в различных сферах:
- Создание контента: озвучка роликов, подкастов, стримов
- Разработка игр: озвучка персонажей без найма актёров
- Аудиокниги: разные голоса для персонажей
- Автоматизация: голосовые уведомления, IVR-системы, ассистенты
Портативная версия Qwen3-TTS
Доступна портативная версия Qwen3-TTS Portable PRO, которая включает:
- Русифицированный интерфейс
- Установка в один клик
- 50+ готовых голосов в комплекте
- Поддержка NVIDIA GPU и CPU
Системные требования
- NVIDIA GPU с 8+ ГБ видеопамяти (или CPU)
- Windows 10/11 64-bit
- 16 ГБ оперативной памяти
- 20 ГБ свободного места на диске
Заключение
Qwen3-TTS представляет собой мощный инструмент для создания реалистичной речи. Её возможности и доступность делают её привлекательной для широкого круга пользователей.







