
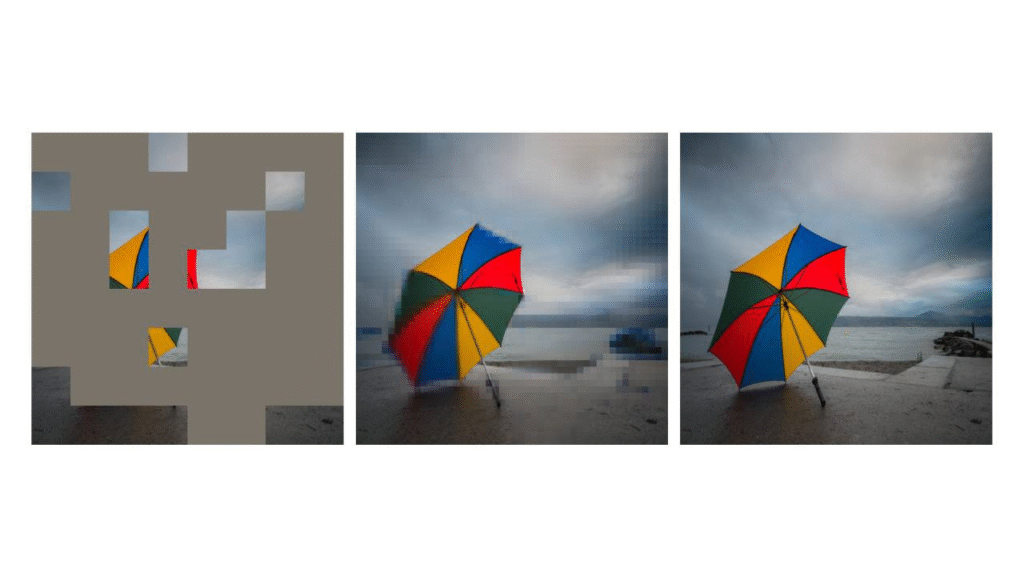
Исследователи из Meta AI разработали инновационную модель обработки изображений Pixio, которая обучается исключительно за счет реконструкции пикселей. Этот подход позволяет Pixio превосходить более сложные методы оценки глубины и 3D-реконструкции, несмотря на меньшее количество параметров и более простой подход к обучению.
Новый подход к обучению моделей ИИ
Традиционный способ обучения моделей ИИ пониманию изображений заключается в том, чтобы скрыть части изображения и позволить модели заполнить недостающие области. Однако этот метод, известный как маскированный автокодировщик (MAE), недавно считался менее эффективным, чем более сложные методы, такие как DINOv2 или DINOv3.
Улучшенная модель Pixio
Исследовательская группа Meta AI в своем исследовании показала, что это не всегда так: их улучшенная модель Pixio превосходит DINOv3 в ряде практических задач. Pixio основана на фреймворке MAE, представленном Meta в 2021 году, но с тремя основными изменениями:
- Усиление декодера — части модели, которая восстанавливает отсутствующие пиксели.
- Увеличение замаскированных областей: вместо небольших отдельных квадратов теперь скрыты более крупные смежные блоки.
- Добавление нескольких токенов [CLS] — специальных токенов, размещенных в начале входных данных, которые объединяют глобальные свойства во время обучения.
Преимущества Pixio
Pixio использует более простой подход: изображения, которые сложнее восстановить, чаще появляются во время обучения. В тестах производительности Pixio с 631 миллионом параметров часто превосходит DINOv3 с 841 миллионом параметров. При оценке монокулярной глубины, вычислении расстояний по одной фотографии, Pixio на 16 процентов точнее, чем DINOv3.
Применение Pixio
Pixio также лидирует в области обучения роботов, где роботам необходимо делать выводы о действиях на основе изображений с камер: 78,4% по сравнению с 75,3% у DINOv2. Pixio обучается исключительно на синтетических изображениях и предоставляет точные оценки глубины в шести реальных тестовых сценариях.
Future developments
Исследователи предполагают, что следующим шагом может стать обучение на основе видео. Используя видео, модель сможет научиться предсказывать будущие кадры на основе прошлых; это более естественная задача, не требующая искусственного маскирования. Команда опубликовала код на GitHub.







